
Flamingo Architecture
The Bridge Between Vision and Language
Table of Contents
Introduction: The Grounding Problem and the Mono-Modal Barrier
The Why: In-Context Learning for the Visual World
2.1 The Fine-Tuning Bottleneck
2.2 The Physics of Few-Shot Learning
2.3 The Interleaved Data Hypothesis
2.4 The Generalist vs. The Specialist
The Anatomy: A First-Principles Decomposition
3.1 The Architectural Philosophy: “Do No Harm”
3.2 The Foundation: Freezing the Giants
3.3 The Connector: The Perceiver Resampler
3.4 The Synapse: Gated Cross-Attention Dense Blocks
The Implementation: Training Dynamics and Infrastructure
4.1 The Data Engine: M3W, ALIGN, and LTIP
4.2 Causal Masking in Multimodal Sequences
4.3 The Mathematical Formulation of the Objective
4.4 Optimization and Hardware (TPUv4)
Comparative Analysis: Flamingo in the 2026 Landscape
5.1 The Connector Wars: Resampler vs. MLP (The LLaVA Divergence)
5.2 The Lineage: From Flamingo to Gemini
5.3 Open Source Replications: OpenFlamingo and IDEFICS
5.4 Video Understanding: The Temporal Dimension
The Critical Take: Strengths, Limitations, and Architectural Legacy
6.1 The Triumph of Interaction
6.2 The Resolution/Token Trade-off
6.3 Hallucination and the Limits of Frozen Backbones
Benchmark Comparison
Conclusion: The End of the Beginning
1. Introduction: The Grounding Problem and the Mono-Modal Barrier
In early 2022, AI was split into two different camps. We had models that could talk and models that could see, but they lived in different worlds.
On one side, we had Large Language Models (LLMs) like GPT-3 or Chinchilla. They were incredibly fluent. They could write code, summarize papers, and mimic human conversation.
But these models were “disembodied.” They understood a “sunset” only as a statistical relationship between tokens. They knew “red” often follows “sunset,” but they had never processed a single photon. They were brains in a jar, hallucinating a reality they couldn’t actually see.
On the other side, we had Computer Vision (CV). Architectures like Vision Transformers (ViT) were masters of pixels. They could classify a thousand dog breeds or find a tumor in an MRI with superhuman accuracy.
However, these models were basically mute. They could output a label like “tabby cat” with high confidence, but they couldn’t tell you a story about the cat. They were eyes without a voice. They lacked the “glue” of language to describe relationships or causality in a scene.
The “Mono-Modal Barrier” was this hard wall between seeing and talking. Bridging it isn’t as simple as just sticking a vision vector onto a text vector. Early image-captioning models were brittle; they could label an image, but you couldn’t actually have a conversation with them.
Flamingo, released by DeepMind in 2022, was the first architecture to really break this barrier. It wasn’t just a single model. It was a blueprint for how pixels could talk to symbols.
The core idea behind Flamingo is the “Convergence Hypothesis.” We suspect that the reasoning patterns an LLM learns from text aren’t actually specific to text. Text is just a very efficient compression format for human logic.
If we can “transcode” visual data into a format the LLM understands, we might get visual reasoning “for free.” The LLM’s existing logic engine can then be applied to images.
This is a massive engineering challenge because of the “bandwidth mismatch.” Images are continuous, noisy, and high-dimensional think millions of pixels. Text is discrete and symbolic.

From where we stand in 2026, we define a real Visual Language Model (VLM) by three specific traits that Flamingo pioneered:
First, Interleaved Input. The model must handle arbitrary sequences like Image -> Text -> Image -> Text. This is how the real world works, like a textbook or a web page.
Second, Open-Ended Generation. It shouldn’t just pick from a list of labels. It needs to generate free-form text to describe, reason, and converse.
Third, Few-Shot Adaptation. You should be able to show two or three examples of a new task in the prompt, and it should “get it” immediately without any new training or gradient descent.
Flamingo was the proof of concept that you could hit all three of these goals in one system.
2. The Why: In-Context Learning for the Visual World
2.1 The Fine-Tuning Bottleneck
Before Flamingo, if you wanted a vision model to do something specific like spotting cracks in solar panels you had to “fine-tune” it. You’d take a pre-trained model like a ResNet, gather 5,000 labeled photos of solar panels, and run gradient descent to update the weights.
This process is a major headache. First, you need a ton of data. Second, you run into “catastrophic forgetting” while the model learns about solar panels, it might forget how to identify dogs or cars. Third, it’s a deployment nightmare because you end up with a different model instance for every single task.
GPT-3 changed this for text using In-Context Learning (ICL). You didn’t change the weights; you just gave the model a few examples in the prompt and let it complete the pattern. The “learning” happened in the activation space, not by updating the actual parameters. Flamingo’s main goal was to bring this same “show and tell” capability to the world of pixels.

2.2 The Physics of Few-Shot Learning
Under the hood, few-shot learning isn’t magic. It’s the attention mechanism doing a lot of heavy lifting. When Flamingo looks at a new image, say, an iguana it’s looking back at the previous examples in its context window (like a dog and a cat).
The model computes a similarity metric across these frames. It’s effectively asking, “How does this new set of pixels relate to the previous ones, and what text followed those?” It figures out the “latent task” it realizes you’re playing a game where it needs to name animal species.
To get this to work, you can’t just train on simple image-caption pairs. If a model only ever sees one image followed by one caption, it never learns to “look back” to find a pattern. It has to be trained on sequences to understand that the past informs the present.
2.3 The Interleaved Data Hypothesis
The DeepMind team realized that the structure of your training data determines what your model can actually do. If you want a model that can handle sequences of images and text, you have to train it on sequences.
In 2022, most datasets were just “pairs” one image, one alt-text. But the web isn’t a collection of pairs; it’s a messy, beautiful sequence. A blog post has text, then an image, then a caption, then more text.
DeepMind built the M3W (MultiModal Massive Web) dataset to capture this. By training on these long sequences, Flamingo learned the “syntax” of the world. It learned that an image can be a noun, an illustration, or a piece of context. This is what actually unlocks the ability to follow instructions.
2.4 The Generalist vs. The Specialist
Flamingo represents the shift from “Specialist AI” to “Generalist AI” in vision. A specialist model, like a YOLO detector, is great at one thing but breaks the moment you move outside its lane.
A generalist like Flamingo might not beat a specialist on every single niche benchmark, but it has “infinite zero-shot” potential. It can try any task you can describe or show it.
Looking back from 2026, we see Flamingo as “Generalist Zero.” We still use specialists for high-speed edge devices, but we usually build them by distilling the knowledge out of these massive, flexible generalists.
3. The Anatomy: A First-Principles Decomposition
Flamingo isn’t one single model. It’s a “chimera” three distinct parts stitched together. To make this work, the engineering team followed a simple rule: “Do No Harm.”
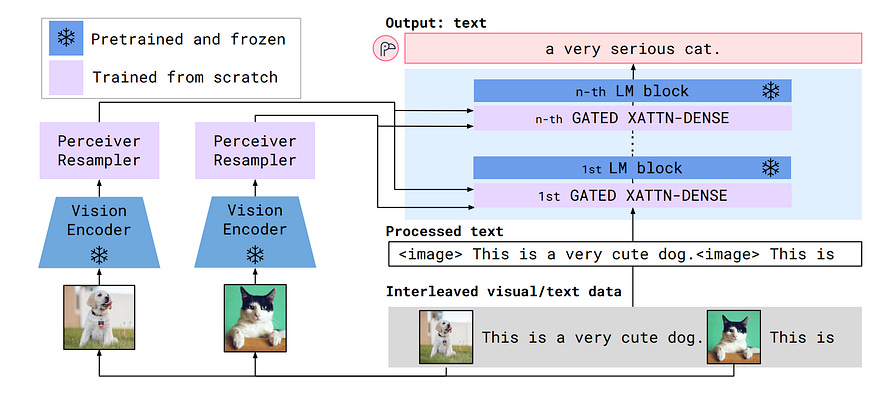
3.1 The Architectural Philosophy: “Do No Harm”
If you take a perfectly good Language Model (LM) and try to retrain it to see images, you usually break it. The noisy gradients from the vision task act like a lobotomy, destroying the model’s ability to write coherent English.
To avoid this, Flamingo freezes the Vision Encoder and the Language Model. They are immutable. You only train the “glue” that connects them. This guarantees the model stays as smart as the base LM it started with.
3.2 The Foundation: Freezing the Giants
For the eyes, Flamingo uses a Normalizer-Free ResNet (NFNet-F6). In 2022, most people were moving to Vision Transformers, but ResNets were still incredibly stable on TPUs.
The “Normalizer-Free” part is key. Standard ResNets use Batch Normalization, which is a nightmare in large-scale distributed training because it creates weird dependencies between images in a batch. NFNets swap this for Adaptive Gradient Clipping (AGC).
The output is a grid of feature vectors. If you feed it a high-res image, you get a 2D map of data. Crucially, this encoder was pre-trained like CLIP. It already knows that the pixels for “dog” should align with the word “dog.”
For the brain, Flamingo uses Chinchilla. DeepMind had recently discovered “Scaling Laws” showing that most models were too big and not trained on enough data. Chinchilla was the “compute-optimal” result smaller, faster, and trained on much more text.
3.3 The Connector: The Perceiver Resampler
This is the most clever part of Flamingo. It solves the Resolution-Sequence Trade-off.
If you take a video with 30 frames, and each frame gives you 256 visual tokens, you suddenly have 7,680 tokens. Standard Transformers have a computational cost of O(L2) . Squaring that sequence length makes the math explode. You’d need a massive amount of memory just to “see” a short clip.
But visual data is redundant. A thousand blue pixels just mean “blue sky.” We don’t need all of them. Flamingo uses a Perceiver Resampler to compress thousands of visual features into exactly 64 visual tokens.
The math uses Cross-Attention. We define 64 “Latent Queries” Qlat which act like empty buckets. These buckets look at the visual features Xf and pull out the most important info.
Because Qlat is fixed at 64, the cost scales linearly O(M) with image size. Whether you feed it a tiny thumbnail or an hour of video, the Language Model only ever sees 64 tokens per frame.
This 64-token limit is why Flamingo can’t read tiny text on a map it literally squashes that detail away for the sake of efficiency.
3.4 The Synapse: Gated Cross-Attention
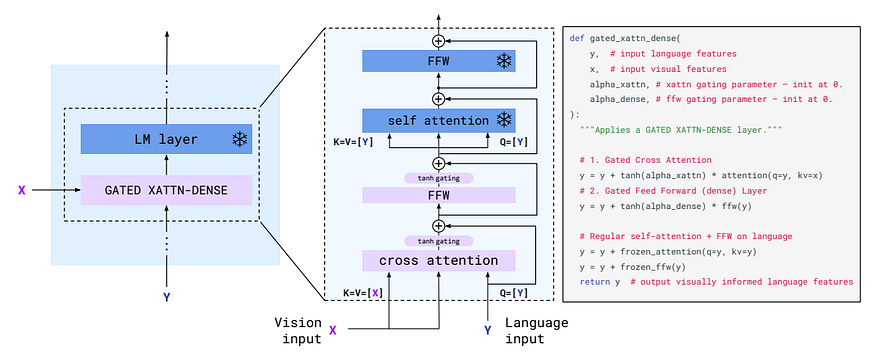
Now we have 64 visual tokens. We need to inject them into the frozen Chinchilla brain. Since we can’t change Chinchilla’s existing layers, we “sandwich” new layers in between them.
We use Gated Cross-Attention. These layers allow the text tokens to “look back” at the visual tokens. But there’s a problem: at the start of training, the new layers are random noise. If you just add noise to Chinchilla, it will stop working.
DeepMind solved this with Tanh Gating. They multiply the output of the new layer by tanh(α) , where α starts at zero.
Because tanh(0) = 0 , the visual branch is invisible at the start. The model starts as a pure text model. As training goes on, the optimizer slowly increases α, “turning up the volume” on the visual signal. This lets the model learn to see without ever breaking its ability to talk.
4. The Implementation: Training Dynamics and Infrastructure
4.1 The Data Engine: M3W, ALIGN, and LTIP
Architecture is the engine, but data is the fuel. Flamingo’s performance comes from a specific training cocktail. DeepMind didn’t just use standard image-label pairs; they used three different types of data.
The “secret sauce” is M3W (MultiModal Massive Web). They scraped 43 million webpages but kept the original document structure. If a blog post had an image, then a paragraph, then another image, M3W preserved that exact sequence.
This taught Flamingo the “spatial logic” of the web. It learned that “the photo above” actually refers to something specific. Most models only see a single image and a single caption, but Flamingo learned how images and text dance together in a long-form story.
They also mixed in ALIGN (1.8 billion noisy pairs) for broad vocabulary and LTIP for high-quality, descriptive captions. For motion, they used VTP, a dataset of short video clips. M3W provided the logic, while the others provided the encyclopedic knowledge.
4.2 Causal Masking in Multimodal Sequences
When training on these sequences, you have to make sure the model doesn’t “cheat.” It shouldn’t be able to look at an image that appears later in the document to predict a word that comes before it.
To keep things efficient, Flamingo uses a Single-Image Cross-Attention constraint. A text token only “looks” at the image that immediately preceded it. If the sequence is Image1 -> Text1 -> Image2 -> Text2, Text2 only attends to Image2.
You might wonder: “Doesn’t the model forget Image1?” Not quite. Text2 still attends to Text1 via the standard language model layers. Since Text1 already “saw” Image1, the information is passed along through the text. This saves a massive amount of compute.
This is enforced using a masking matrix. We hard-code the attention mechanism so that text tokens are literally blind to any images except the one that just appeared. It’s a simple, elegant way to handle long documents without the math exploding.
4.3 The Mathematical Formulation
The training goal is just standard Next Token Prediction, but with a visual twist. We want to maximize the probability of the next word given the words and images that came before it.
In plain English: we are training the model to guess the next word yl. It uses all previous words y<l and the images x that appeared before it. It’s the same way GPT-4 is trained, just with a much richer context.
4.4 Optimization and Hardware (TPUv4)
Training the 80B version of Flamingo was a massive engineering project. It required 1,536 TPUv4 chips running for about 15 days.
The team used JAX and Haiku for the implementation. JAX is great for this because its functional style makes it very easy to manage “frozen” parameters (the brain) and “trainable” parameters (the glue) without getting confused.
Interestingly, they didn’t use a learning rate decay. They kept the learning rate constant, which is unusual for large-scale training. But because most of the model was frozen, the optimization landscape was stable enough to handle it.
5. Comparative Analysis: Flamingo in the 2026 Landscape
Flamingo dropped in 2022. From the vantage point of 2026, we can see exactly how it changed the game by looking at the models that followed in its wake.
5.1 The Connector Wars: Resampler vs. MLP
The biggest debate after Flamingo was a simple engineering question: “How should we hook the visual eye to the linguistic brain?”
Flamingo chose the Perceiver Resampler. It’s a sophisticated, fixed-token approach. On the other side, LLaVA (2023) went for the “keep it simple” route using a Linear Projection (MLP).
The MLP approach just takes the raw grid of features, say, 256 tokens and maps them directly into the language model. Because it doesn’t compress anything, it’s much better at high-detail tasks like OCR. If there’s a tiny “Exit” sign in the corner, a Resampler might “average” it away into a general “door” concept. The MLP keeps every pixel’s contribution.
By 2026, the industry split in two. High-fidelity models for photos (like GPT-4V) use the MLP approach with high-res cropping. Video models (like Gemini 1.5) still lean on Resamplers. You simply can’t afford to keep every token when you’re processing a 10-minute clip. Flamingo’s Resampler was the ancestor of all efficient video understanding.
5.2 The Lineage: From Flamingo to Gemini
Flamingo was essentially the prototype for Gemini. While Gemini is a “native” multimodal model meaning it was trained from scratch to see and talk, rather than being stitched together from frozen parts it inherited Flamingo’s soul.
Gemini’s training set is just a massive, scaled-up version of the M3W interleaved data. Its ability to handle hours of video is the same logic Flamingo used, just with a much larger context window. Flamingo proved the concept; Gemini scaled the engineering.
5.3 Open Source Replications: OpenFlamingo and IDEFICS
Since DeepMind never released the original Flamingo weights, the community had to build their own. OpenFlamingo and Hugging Face’s IDEFICS were the most successful attempts.
These projects proved that the architecture wasn’t just “DeepMind magic.” By training on OBELICS (an open-source version of M3W), they showed that the “interleaved data hypothesis” was 100% correct. If you don’t have that specific data structure where images and text mix naturally, the model never learns how to follow visual instructions.
5.4 Video Understanding: The Temporal Dimension
One of the most surprising things about Flamingo was how it handled video. It didn’t use complex 3D math or specialized “Temporal Transformers.” It just sampled 8 frames, ran them through the Resampler, and fed the resulting 8 \times 64 tokens to the brain.
This simple “sampling” approach actually beats models specifically designed for video. It turns out that if you have a smart enough language model, it can fill in the “motion gaps” itself. You don’t need a model that understands 3D space if the model understands the logic of what happens between two photos.
6. The Critical Take: Strengths, Limitations, and Architectural Legacy
6.1 The Triumph of Interaction
Flamingo’s biggest win was making vision programmable. Before this, if you wanted to detect “unsafe construction zones,” you had to build a custom detector from scratch.
With Flamingo, you just talk to it. You show it a photo and say “Safe,” then another and say “Unsafe.” By the third photo, it gets the vibe. This shifted the bottleneck from “weeks of engineering” to “minutes of prompting.” It turned computer vision into a software interface.
6.2 The Resolution/Token Trade-off
The model’s Achilles’ heel was that Perceiver Resampler bottleneck.
By squashing every image into exactly 64 tokens, you’re effectively throwing away the “high-frequency” details. If there’s tiny text or a small object in the background, the Resampler treats it like background noise.
This is why LLaVA, which used a simpler MLP connector and kept 576+ tokens, eventually beat Flamingo on benchmarks like TextVQA. LLaVA kept the “pixels” while Flamingo only kept the “gist.”
From our 2026 perspective, we see Flamingo as the “fixed-rate” era of compression. Modern models are “variable-bitrate” they use 10 tokens for a picture of a blank wall but 1,000 tokens for a dense map or a page of text.
6.3 Hallucination and the Frozen Brain
Because the Chinchilla brain was frozen, it sometimes suffered from “stubbornness.” If the language model had a very strong prior like believing it’s always sunny in a certain context it would sometimes ignore the visual tokens entirely.
You could show it a photo of a rainy day, but if the text prompt felt like a “sunny day” story, the model would confidently describe the sun. The visual signal was sometimes too weak to override the internal weight of a 70B parameter text model.
This led the field toward Full Fine-Tuning (updating the brain and the eyes together) or Native Multimodal training. We realized that for a model to truly “believe” what it sees, the vision signal needs to be baked into the weights, not just whispered to the model through a side-channel.
7. Benchmark Comparison
Flamingo-80B set the initial bar. LLaVA (13B) crushed that bar just a year later with a much smaller model, purely by using high-quality instruction tuning data and avoiding the lossy compression of the Resampler for static images. However, for true few-shot, in-context learning (the "32-shot" column), Flamingo remained the reference standard until the Gemini era.
8. Conclusion: The End of the Beginning
In the history of AI, Flamingo will be remembered as the Great Connector. It was the bridge that finally allowed the solitary genius of Large Language Models to open their eyes.
DeepMind proved that you don’t need to rebuild the brain from scratch to add vision. If you have a powerful enough language model, you just need to wire the “optic nerve” correctly to the existing logic centers.
Flamingo established the “Type-A” architecture what we now call Deep Fusion via Cross-Attention. It also proved that interleaved web data (M3W) isn’t just a luxury; it’s a requirement for models that need to follow complex, multi-step visual instructions.
It also validated the Perceiver Resampler as the gold standard for handling video. While the specific parts have swapped out over the years NFNets gave way to SigLIP, and Chinchilla evolved into Gemini the fundamental topology Flamingo pioneered is still visible in the DNA of almost every multimodal model we use in 2026.
The most important lesson from Flamingo is that text is a universal interface. By transcoding pixels into a format the language model can “digest,” we unlocked visual reasoning almost for free.
DeepMind showed the world that vision isn’t just about labels or bounding boxes. It’s about conversation, context, and the ability to learn a new task on the fly. Flamingo didn’t just break the mono-modal barrier; it showed us that the barrier was mostly an engineering illusion.
If you want to explore more about Vision Language Models and learn how to build them on your own, then consider checking out our platform Togo AI Labs. And subscribe to our newsletter for more such exciting articles.
Check out our socials: LinkedIn | Togo AI Labs | YouTube